





You can’t fix what you can’t see. Collibra Data Quality & Observability helps you eliminate data quality blind spots. Monitor, detect and fix data anomalies while connecting every quality signal to the data products, policies and AI models your business runs on. Deliver data your people actually trust and reliable context for AI agents.













































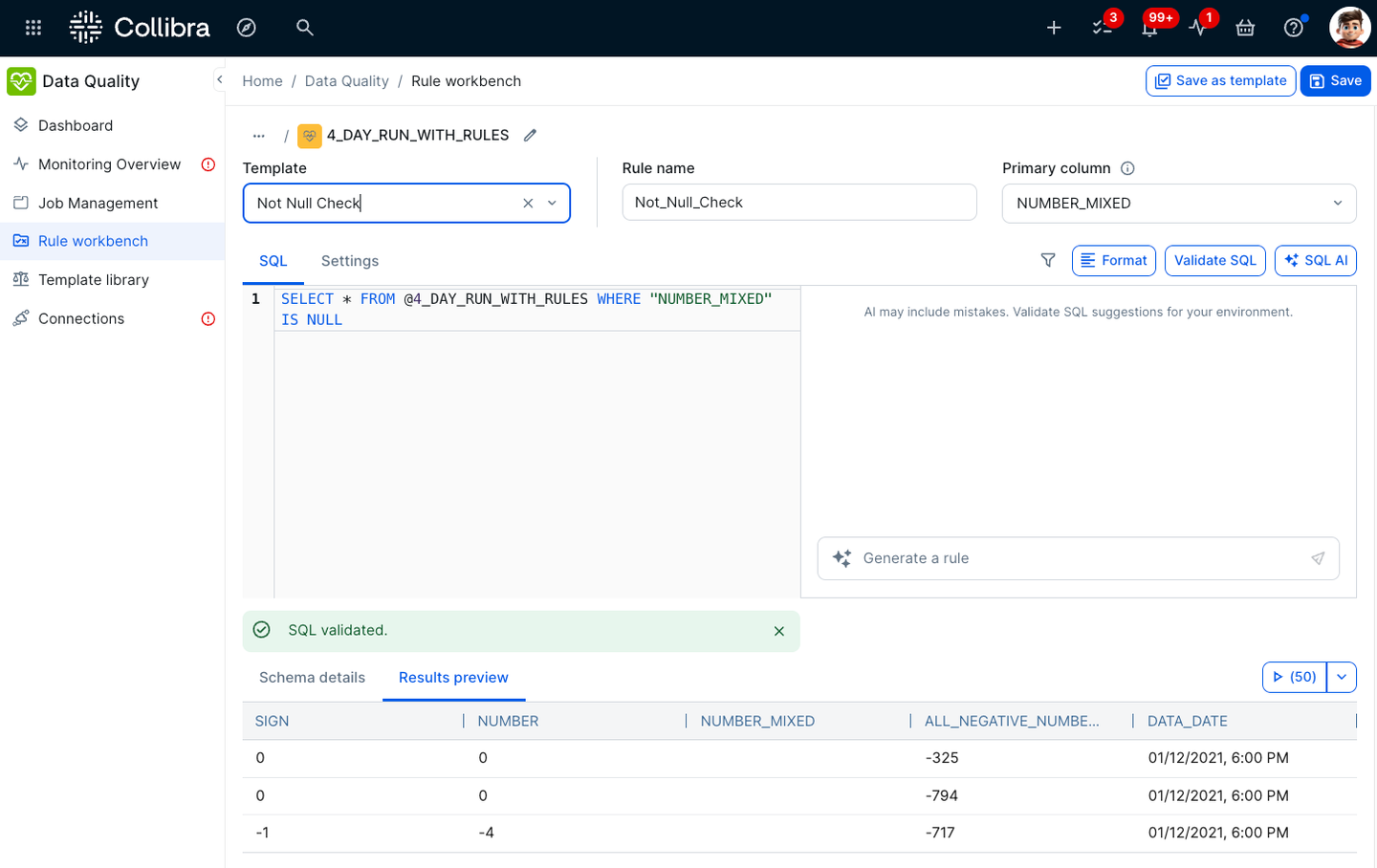
Scale data quality coverage in days, not months
AI removes the guesswork from rule authoring, reducing bottlenecks. Reusable rule templates let teams standardize quality checks and scale coverage consistently across new datasets and domains in standard SQL. The result is that you can go from onboarding to measurable quality improvement in days instead of months so coverage keeps pace as your data estate grows.