



Data is everywhere. And at every point data gets created, processed, or used in your organization, its quality is at risk. The impact of data quality on businesses is thoroughly analyzed, and Gartner quotes the organization level average of $12.9 million per year. While the market offers several enterprise solutions for data quality improvement, this figure is not going away quickly. It may indeed worsen, considering the onslaught of data and the scaling challenges of traditional solutions. A recent HBR article calls for action, noting that on average, 47% of recently created data records have at least one critical error.
What is predictive data quality?
Data teams often get constrained by manual rule writing and management, with limited data coverage and a siloed view of data quality. It becomes more critical as data producers and data consumers operate in silos, failing to identify the opportunities to improve data quality in a business context. As a result, organizations lack an enterprise data quality foundation to respond to regulatory, analytics, and AI demands in a scalable and cost-efficient way.
Making sure data is of a high quality involves rules. Lots and lots of rules. Predictive data quality applies the latest advancements in data science and machine learning to the problem of data quality. An intelligent data quality system can evolve rules on-the-fly. The rules can adapt to the changing data landscape to ensure they reflect what’s happening with the data and in the business. Identifying duplicates, missing records, inconsistent data, and other issues proactively, predictive data quality delivers trusted data for trusted insights.
Gartner forecasts that by 2022, 60% of organizations will leverage ML-enabled technology for data quality improvement. The use of AI and ML algorithms improves the predictive tasks of detecting quality issues, quickly estimating their impact, and prioritizing them.
How predictive data quality works
Monitoring streaming data in real-time, predictive data quality identifies issues as soon as they appear, ensuring that only high-quality data powers all applications. Automatically profiling datasets, predictive data quality produces alerts when any change in data creates quality concerns. Data stewards or DataOps can use impact scoring to triage issues quickly, providing high-quality data pipelines for high-quality results. A recent McKinsey study on automation and AI concludes that, when done right, automation has proven to deliver real benefits, including distinctive insights and increased scalability.
For an enterprise-scale data reliability solution, organizations focus on four key drivers:
- Auto-discovery of data quality issues without domain experts and manual rule writers, automatically uncovering data drift, outliers, patterns, and schema changes.
- Visibility into data issues, tracing data movement to narrow the focus of root cause investigations.
- An effective prioritization mechanism, focusing on business-critical data with maximum impact, initiating remediation workflows with the right data owners.
- Scalability across large and diverse databases, files, and streaming data.
One of the significant benefits of ML-powered predictive data quality is automated monitoring without moving any data, which can easily scale as your business grows. It can quickly scale across large, diverse databases, files, and streaming data, to continuously assure high data quality.
Maintaining continued compliance with privacy regulations such as GDPR, CCPA, CCAR, and HIPAA is essential for meeting business objectives and avoiding fines. ML-enabled auto-discovery can detect sensitive information across the data landscape to ensure privacy compliance. By quickly generating audit data and reports with self-service data quality, you can speed up the compliance process for highly regulated industries like finance and healthcare.
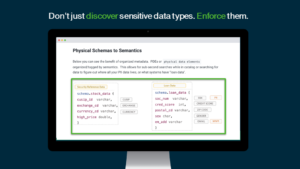
Why you need an enterprise-scale approach to data quality and observability
The challenges of data and analytics in today’s business environment require new ways of thinking. Who are the data producers in your organization? Who are the data consumers? If you look meticulously, they are both systems and people. And they require trusted, compliant, relevant and always-on data. United by data brings them all together, delivering true unification across your organization. The next obvious question is – how? Leveraging tools and methodologies of data governance, data lineage, data catalog and data quality together can deliver far more benefits than individual practices. Most of the data stewards are already aware of the synergies across these practices:
- Data quality + data lineage enables prioritizing data quality issues by business impact.
- Data quality + data governance ensures escalating priority data quality issues to the right data owners.
- Data quality + data catalog connects business context around critical data elements with data quality issues.
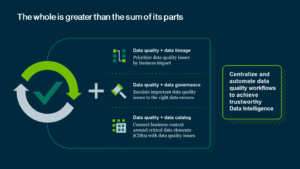
When you harness these synergies as a fully integrated system, these practices can centralize and automate data quality workflows for continuous, self-service, predictive data quality. United by data across silos connects data producers with data consumers to promote collaborative data quality improvement. An enterprise-scale approach to data reliability maximizes these synergies to improve business decisions.
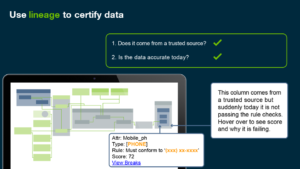
1. Prioritize data issues with lineage visualization
If you only have time to fix two things today, which of the twenty do you fix? Business impact ranking via graph (lineage) analysis can help.
Delivering trusted data needs a complete understanding of data, where it comes from, and how it gets transformed during its entire journey. Data lineage can certify that a particular dataset comes from a trusted source so that you focus on its quality alone. It also provides a quality score indicating the level of accuracy at that instant, which you can use for a roadmap to improve quality.
2. Escalate with data governance workflows
Gartner recommends that the top 3 priorities for Chief Data Officers (CDOs) in 2021 are creating a data-driven culture, developing a data and analytics strategy, and standing up a data/ information governance program. Data governance is uniquely essential today because that’s the only way to maximize the value of the large and diverse data assets.
You can create a robust foundation of data governance to establish a shared understanding of data. Data governance workflows simplify your data stewardship tasks for business agility. Combined with the self-service, predictive data quality, the collaborative environment enables enterprise-wide contribution to quality. A robust data ownership model empowers you with a streamlined two-step approach:
- Identify issues with predictive data quality.
- Escalate data quality issues directly to data owners with automated workflows.
Self-service data quality empowers business users to build trust in data, leveraging the following essential features:
- Unified, easy-to-understand scoring system across all types of data storage.
- Interactive, customizable dashboards for quick insights into data quality.
- Personal alerts to proactively identify and assign data quality issues.

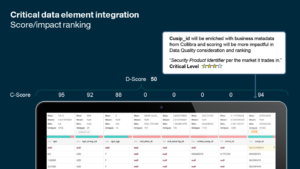
3. Discover context with data catalog
Data quality issues often do not provide sufficient context about how they relate to your business. Organize your data assets with a data catalog so that data consumers in your organization discover and understand data in the full context to generate powerful business insights.
Data catalog streamlines data access with context and governance using the following features:
- ML-driven discovery, profiling, and curation of data assets for a unified view.
- Automatic classification and tagging for an enhanced data shopping experience.
- Review and ratings for fast insights into trusted data assets.
A successful soccer team capitalizes on individual skills to create a cohesive and coordinated effort, delivering a winning performance. A successful organization united by data leverages an enterprise-scale approach with different practices and tools to deliver a winning strategy.


