Recently I talked to a Data Governance Program Manager of a large enterprise customer about how difficult it was for him get a corporate-wide view on data quality. I learned that large companies can have many different rules engines to check quality and curate data. Each of these tools are good at what they need to do, i.e. technically checking the data quality and fixing it, but what is often missing is business input of data owners. So the true challenges for the data stewards are:
- Getting a consolidated view
- Understanding the data and related processes
- Defining the quality gaps in their own business language
- Defining an effective workflow to process the gaps in the right place by the right people
- Creating an automated feedback loop when the gaps are addressed
To be able to address these challenges, you need an enterprise-wide data governance platform that combines data cataloging, data lineage, data quality, data profiling, and alerting capabilities, supported by machine learning, to enable the data stewards, data analysts, and data scientists, independent of where that data resides.
To date, many organizations have implemented quality checks in a plethora of technical tools across data sources and systems with little or no consolidated view on the quality from a business point of view. In today’s data-driven world where businesses change rapidly, data stewards need more agility to build business rules on the data. That way, they gain insight into how business processes need to change and who in the business they need to collaborate with to solve data issues at their root cause. They also need an integrated approach towards data governance and data quality – not a wide variety of different siloed applications. And if you ask someone like our CTO Stan Christiaens, he says a toolbox approach does not work for data governance. And you’ll see a similar theme in reports from leading analysts such as Gartner and Forrester.
This is a paradigm shift from data quality being a technical, reactive endeavor, to a more proactive approach that makes your data governance initiative much more aligned to the ever-changing business strategy. This approach also transfers the priority setting to the business so the data quality efforts will focus on critical data elements first. It also reinforces the importance of the business taking ownership of their data, as this is the only valid approach to be able to trust your data. Trust is induced by governance, policies, and business quality rules and metrics, enabled by strong and informative data lineage visualisations.
Never before have data stewards, data analysts, and data scientists been able to browse through an all-encompassing catalog of data in their organization. Now, they can see what that data looks like, understand which policies it complies with and what the quality is, and, on top of that, provide the ability to easily set thresholds and rules to actively monitor the quality of the data that they own. And they can do so in one single platform, powered by machine learning through Apache® Spark™, a powerful processing engine built around speed, ease of use, and sophisticated analytics.
In the words of one of our customers, “We’ve tried many traditional data quality and profiling tools with our data stewards, but the interface and terminology remains too technical.”
The key building blocks of a business user centric and data governance focused platform are:
- Self-service onboarding of data structures and easy assembly into logical sets – based on the business needs. This enables you to immediately have a clear and unified picture of your most important data and will allow your data citizens to easily find the right data.
- Multi-dimensional data lineage that allows you to understand all critical aspects related to data: people, processes, and systems
- Traceability that shows how the data flows through your application landscape from source to target for each logical set of data
- Insightful data profiling visualisations including scrambled and anonymized samples of data to help you understand the data for which you need to assume ownership
- Alerts and automated data issue workflows that give you the ability to trigger the right curation processes to fix data problems at the source rather than at report time in a unsustainable way. This will quickly build trust in your company’s data assets
- An Amazon-like shopping experience that allows for controlled and governed data usage across the enterprise
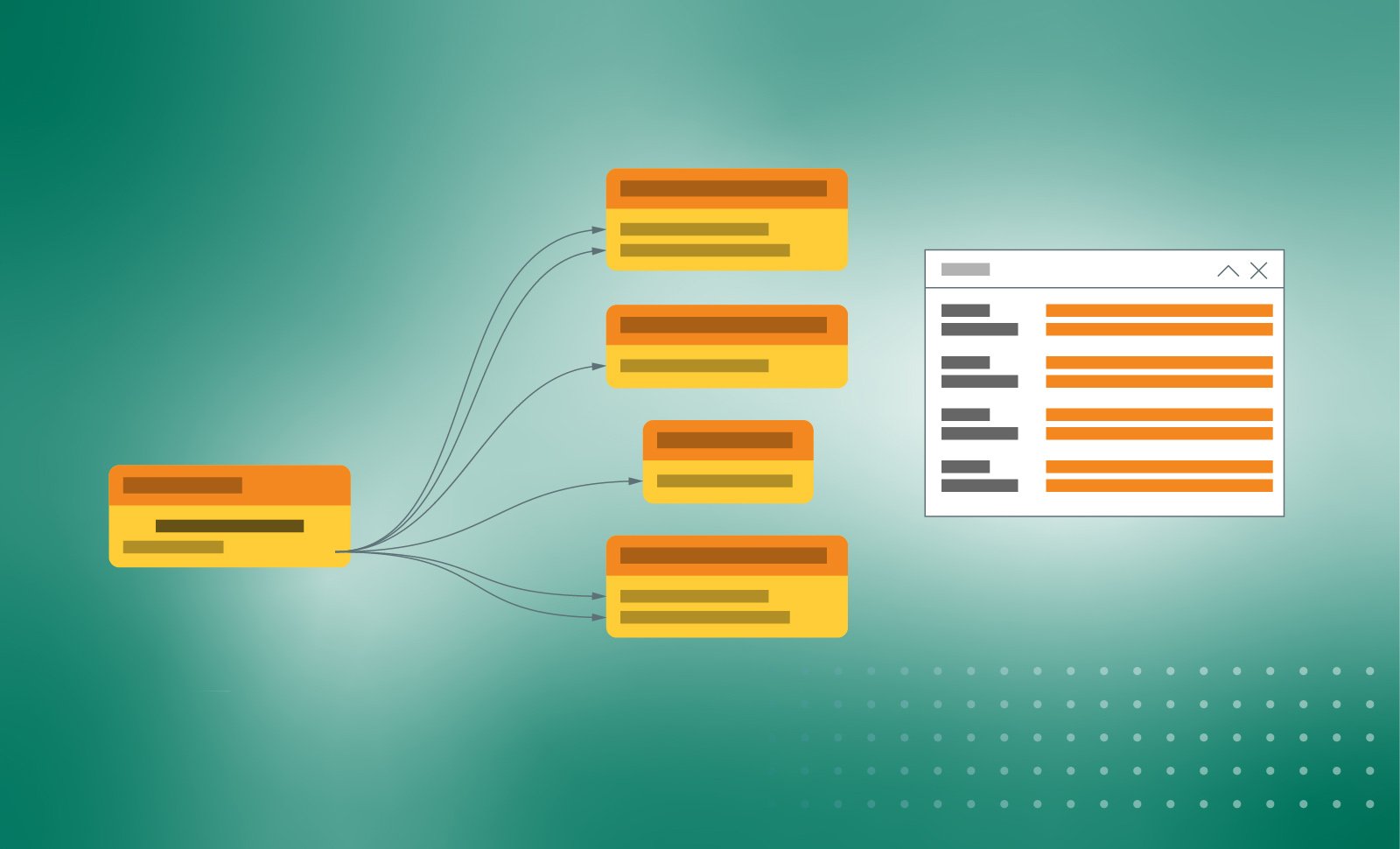
Self-Service Data Shopping
Collibra Catalog helps with the automated onboarding of all the data structures (aka technical metadata) from your company’s source systems of record. And, it logically groups the data into data sets used for reporting, analytics or compliance. Machine learning algorithms make it easy for the data stewards to merge the technical data lineage with a more understandable business context. You can also use other machine learning techniques to detect similar data sets, duplicate business terms, and more. This makes it really easy to clean up your data swamp and purify it to data lake, where it is easy for data citizens and data scientists alike to find trustworthy data sets for any business reporting or data science project. Finally, collaborative features like tagging, user mentioning, rating, and more facilitate the crowdsourcing of business context around your data to make it easier for everyone to find, understand, and trust a data set.
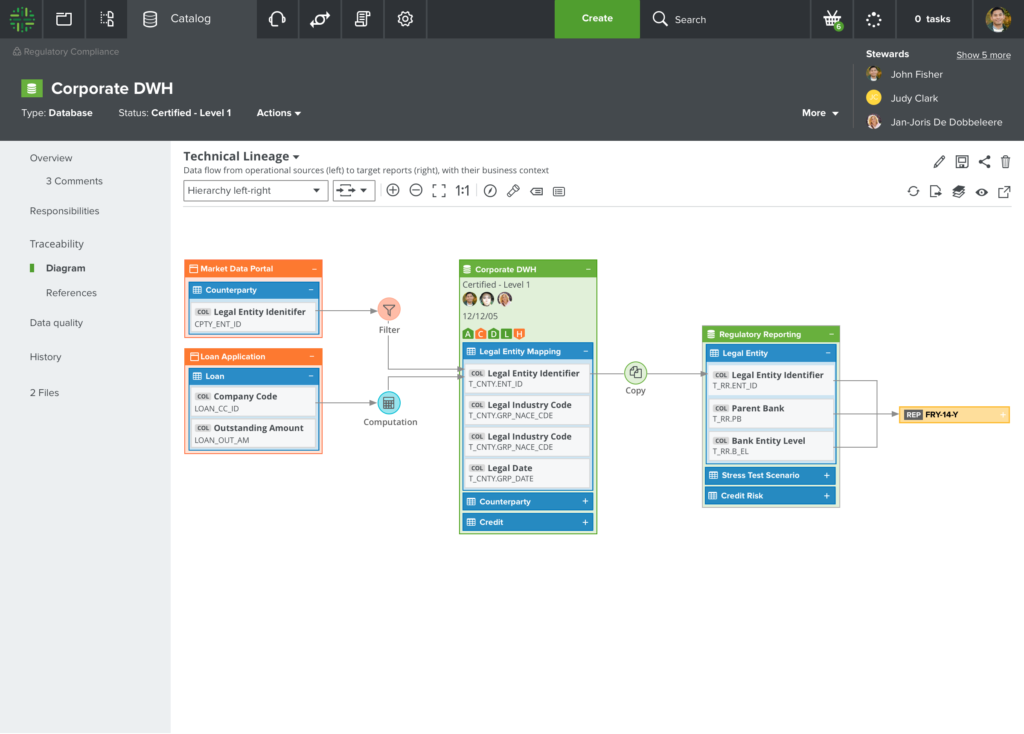
Data Lineage for Everyone with a Focus on Ownership, Quality, and Trust
Collibra data lineage diagrams provide automated “data” lineage to understand the data flows from source systems to critical compliance reports. A layered lineage visualisation is user centric and focused on providing the right insights for the user, depending on the user persona looking at the diagram. Users can easily toggle these layers on or off. For example, the quality on a data lineage from source system to compliance report is key for understanding and trusting, as well as for auditability. Here are just a few examples of what is available in data lineage today:
- Overlay per Data Quality Dimension showing the current average score (green-amber-red) and a trend indication (stable, upwards or downwards)
- Overlay of the number of data quality metrics and rules defined
- Overlay of the number of data quality issues created by status (high-medium-low)
- Overlay of ownership per data assets
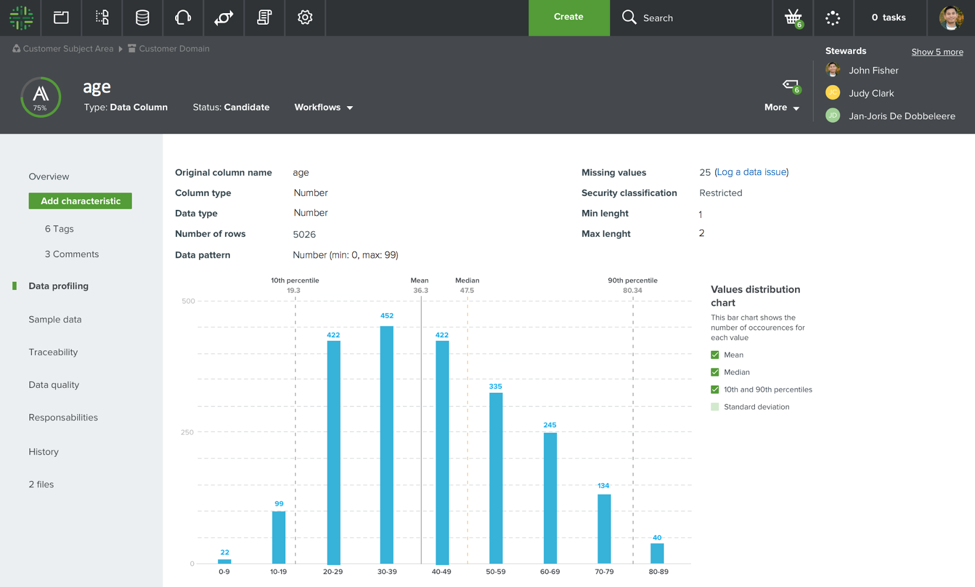
Profiling and Preview Provide Automatic Insight into Data
Catalog’s newest addition, data profiling and data previewing, allows the data stewards to get in touch with the data. They can see, feel, and better understand the data without too much hindrance and dependence on the technical owner of the data. Highly visual data profiling results show key characteristics, distributions, and outliers of the data.
Warning! Don’t govern your data from an ivory tower, use a true data governance platform to get in touch with your data.
Too often, data quality checks are defined from an ivory tower by people who do not know or who never have seen or worked with the data. Data samples are scrambled and sensitive data elements are hidden automatically for the users.
- Stewards can define business data quality rules based upon the data profiling results and scrambled data samples.
- Machine learning techniques will – based upon the available metadata and rules in Collibra – autosuggest data sets for which the same or similar data quality rules apply.
- Stewards can define data patterns (eg account number structure) in Collibra and have the data profiling automatically tag each column that matches the pattern.
- You and your colleagues can brainstorm inside Collibra on what the right data quality measures and metrics are and define them immediately in Collibra. Then, you can build interactive dashboards to allow the business to follow-up and stay up to date with the current state of your data landscape.
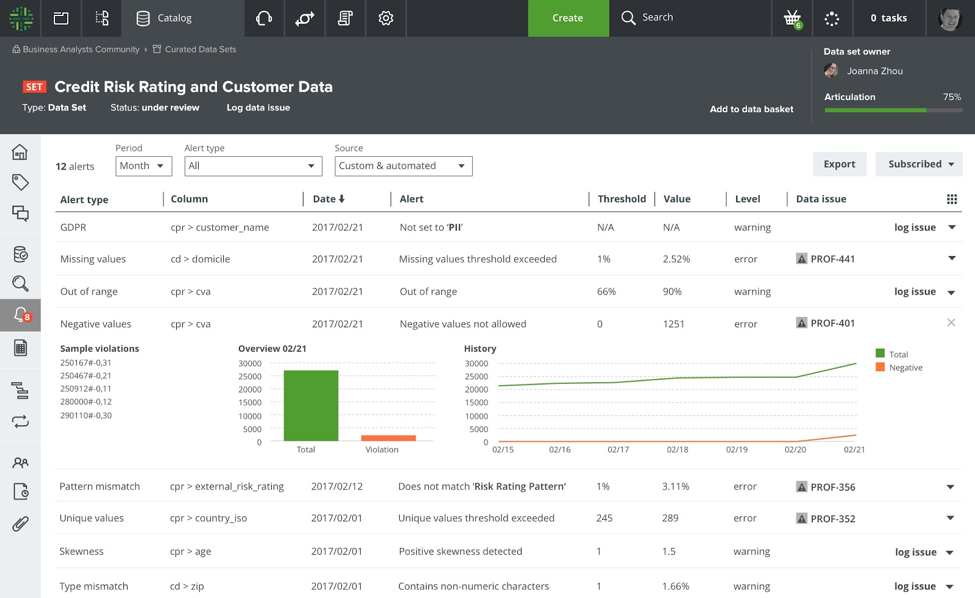
Infuse a Data Quality Awareness through Automated Alerts and Issue Management
Data governance drives data quality. Inject the data quality mentality in your organization via smart alerts that can be defined by the data stewards in a user-friendly way. Or, you can use Spark-enabled machine learning models that suggest alerts for the data stewards based upon anomalies in the profiled data. For example:
- Enable data stewards to define simple relative or absolute thresholds linked to standard email notifications using a user-friendly wizard
- Validate the profiled data against the reference data present in Collibra Reference Data and automatically alert the Reference Data Code Set owner in the event of a mismatch between the profiled data and the code set values
- Provide a catalog of alerts that shows a nice and comprehensive overview of all defined alerts on a data set, presented in tiles showing key attributes of the alert
- Automatically create data issues for every breach against an alert (in Collibra Data Helpdesk) and be assigned to the technical owners of the data against which the breach was detected
As the leader in data governance, Collibra continues to push the boundaries of data through self-service data shopping, data lineage for everyone, data profiling and sample, and auto alerts and issue management. And we welcome input from you. Please subscribe to our User Participation Program.