


Over the past couple of years, I’ve seen the importance of data governance grow across all industries. For some reason though, most people seem to associate data governance with a control function that conjures all sorts of associations of data policing, lack of agility, slow change, and more. Obviously, you need some degree of control to make data governance real, just like a police officer is a control mechanism for whether you are actually wearing your seatbelt (which is good for you) or respect stop signs (which is good for others as well as yourself). However, an often overlooked aspect of data governance is that it must also function as an enablement function because process creates peace of mind and actually gets things done when you are faced with a lot of stakeholders. It’s similar to how traffic lights and speed limits increase traffic flow for the whole system. There is good news for the fans (including myself) of the enablement view, as I have been getting questions about crowdsourcing data governance.
Crowdsourcing means that you “tap into the community:” everybody has equal and full rights as a data citizen and is encouraged to participate freely. And everybody – from the CEO down to the data janitor – has self-service access to add key data elements, propose business metrics, flag a data type, request data sharing, and more. While this may sound wild, it has actually proven to be a very successful collaboration model that can lead to great outcomes (e.g., Wikipedia, Reddit, and Youtube). Powered by an enabling technology platform that includes appropriate clean and control tools (e.g., workflow, commenting, suggestions, machine learning, etc.) you can grow a very collaborative community including norms that provide a very resilient barrier against total chaos.
Before you jump on the crowdsource bandwagon
Now, do I believe that all organizations should go full crowdsource? No, just as I do not believe that the opposite is the solution. Every organization (and in more detail: departments, lines of business, project teams, etc.) has its own context: culture, maturity, priorities, even political factors or tight regulations. There is no single way of doing data governance: in some contexts crowdsourcing will produce fantastic results, and in others it will be a failure. Crowdsourcing is, simply put, the most unlimited side of a control spectrum. And you have to figure out your ideal place on that spectrum.
This variation of context is why the right operating model set up is so important for any data governance initiative, especially the ones that are just getting started. A successful data governance initiative will bring change, and so time becomes yet another dimension for the context. I’ve seen it happen many times: organizations launch with a best-in-class operating model to drive their stewardship. They gain adoption, and the resulting change makes the original operating model obsolete, or rather stretches it to the limit.
This is why I am absolutely convinced that a data governance platform that aims to be successful needs a capability for operating model configuration: your roles, responsibilities, workflows, dashboards, views, use cases, and more. And because organizations are not carved from a single slab of stone, but rather cling together like parts of a living organism, the configuration needs to support federation: some parts of the business (e.g., analytics) will require crowdsourcing while others live in a stricter world and require tight controls (e.g., risk and compliance).
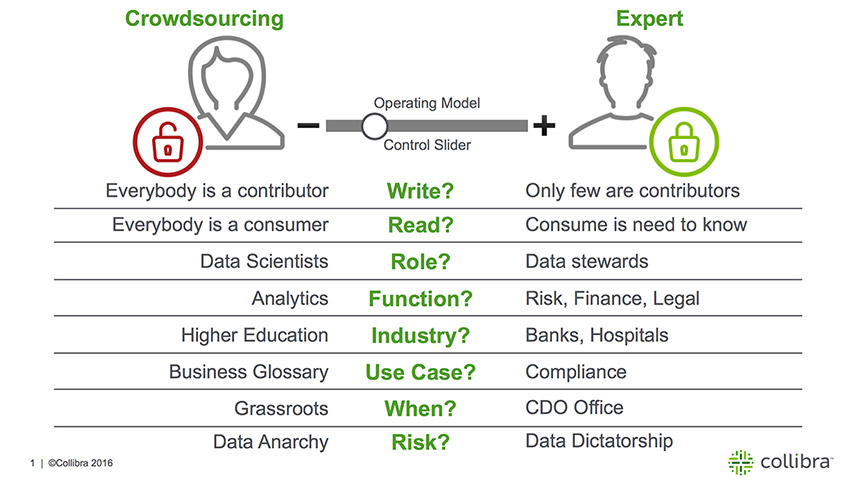
If you are excited by crowdsourcing data governance, and if you are looking for guidance, I would recommend reviewing the diagram at the top of this blog post. I’ve laid out the control spectrum where “no limits” is all the way on the left (“Crowdsourcing”) and “total control” is all the way on the right (“Expert System”). In between, there is a slider: imagine simply sliding your finger from right to left if you want to go more in the direction of crowdsourcing.
As I mentioned before: there is no single way of doing data governance, and you need to figure out the balanced operating model that works for your organization. Keep an eye out for a future blog post where I will show how to set up crowdsourcing in the Collibra Data Governance Center.
