



The explosion of data across organizations has led to a wide variety of ways to store, catalog and use that data. One common organizational theme is a central data lake, which is useful for centrally maintaining as much data as possible and having corporate data engineering store it securely.
But modern data-consuming organizations are discovering that central data lakes have their downsides. The data lake itself is a monolithic, centralized platform, which requires its own set of managers and administrators to apply rules and governance to the data it stores. That means those administrators can become bottlenecks in the flow, transfer and availability of data. Further, due to the fact that the central IT team managing the lake becomes a bottleneck, it is likely “shadow IT” organizations will grow, creating their own lakes, which hampers discoverability from the wider organization.
Data mesh: A self-serve data storage design
A more modern solution to the challenge of storing and sharing data within an organization is the data mesh. The data mesh is a decentralized data architecture that leverages a domain-oriented, self-serve design. Data mesh reflects a shift away from a centralized data platform to a modern distributed architecture where organizations can truly unify data from disparate systems and sources.
The result can be an intuitive, scalable self-serve data model. In a data mesh architecture, each organization can cater to their own data, while at the same time benefiting from a framework of overarching governance and the corporate wide infrastructure. The fact that each team can directly produce their own data means that important context remains with the data, and that consumer teams can directly interact with the data-producing teams. The central IT team will cater for a governance framework which will put guardrails around the corporate data, preventing misuse.
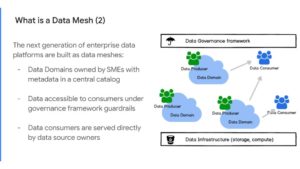
A data mesh architecture allows domains to be owned by subject matter experts, and to let the data contained to be more accessible than data lake data managed by a single small team.
3 steps to data mesh
Google Cloud offers sophisticated tools for quickly onboarding data streams, pre-processing streaming data and data visualization. Google Cloud Dataplex is a data management platform that offers seamless integration with Google-native and open source tools, allowing an integrated analytics experience to curate, secure, and analyze data at scale.
Google Cloud partnered with Collibra to build a data mesh architecture. Through a three-step process, Collibra and Google Cloud built a seamless, scalable, self-service data system.
Step 1: Avoiding the clogged data lake
The first step is to identify and absorb all the data sources coming into the data lake. The data is registered and grouped according to identified taxonomies. Those can include data policies, usage, permissions, ownership, related BI reports and more.
Step 2: Applying the correct policies
Once the data is registered and absorbed, Collibra metadata helps to validate the data, and Collibra Data Quality is used to make sure the right data gets to the right zones. Collibra Data Governance ensures that the right governing policies are applied to the data so that it can be organized with the full context.
Step 3: Building a robust, self-service catalog
After the data is analyzed and organized with the business context, the solution is pushed to Google Cloud Dataplex. The result: A robust catalog that enables self-service for data users across an organization. The resulting data mesh provides an intuitive experience across the enterprise, and its users can rely on data quality and lineage, as well as have peace of mind that the data aligns to all necessary policies.
The benefits of Collibra and Google Cloud’s data mesh platform
Benefit 1: Facilitate faster time to insight by accelerating the time to access and analyze decentralized data
With Collibra and Google Cloud’s data mesh platform, managers of the data lake are no longer at a roadblock, as data consumers across the enterprise are now empowered to shop for and access the data they need. They can access the data more quickly, and that means they can use, analyze and act on it more quickly.
Benefit 2: Enable data owners and producers to respond quickly and scale access with centralized data management
In this system, Collibra and Dataplex allow for standards to be governed centrally, but the implementation of these standards – including policy enforcement, access rights, data quality, business glossary and more – is pushed upstream. The data owners or subject matter experts can decide the rules about all of these standards, removing the roadblock of always going through the data lake management team.
Benefit 3: Optimize the central management of data to foster data literacy across the enterprise
As the volume of data grows and the number of consumers grow, the solution also allows for scaling into the future, so that new data and policies can be ingested under the same decentralized rules, creating more self-service data options.
Watch the on demand webinar to learn more details of how the Collibra platform integrates with Dataplex to combine data from across Google Cloud data products, giving organizations the ability to build a scalable, modern distributed data mesh architecture.


