Find data issues before they become business issues. Ensure reliable data with automated monitoring, anomaly detection and notification.
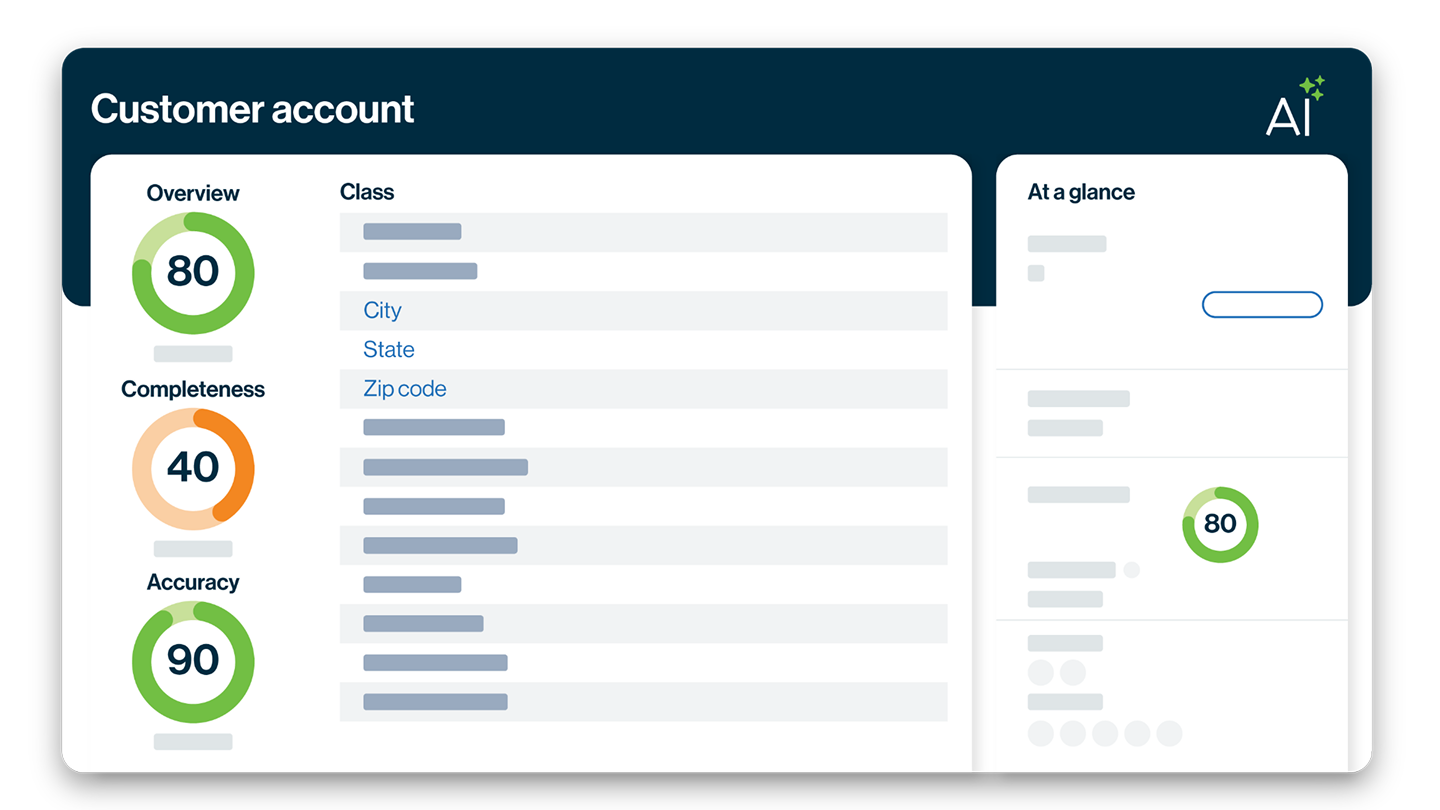
Accelerate data discovery and profiling
Data structure, content, class and sensitivity is automatically identified across sources.


























