Related resources
What is anomaly detection and what are some key examples?
Share on:

Anomaly detection, also called outlier analysis, is the process of identifying unusual patterns, rare events, atypical behaviors, or outliers of a data set. These anomalies differ significantly from the rest of the data. Anomalies usually indicate problems, such as equipment malfunction, technical glitches, structural defects, bank frauds, intrusion attempts, or medical complications.
Some anomalies can be simply infrequent occurrences raising interest, such as the mysterious radio bursts in astronomy data and outliers in demographic data. Investigating anomalies helps interpret the context, eliminate possible causes (if necessary), improve data quality, and fine-tune your data sets.
Uses of data anomaly detection
Anomaly detection plays a critical role in generating business insights and maintaining core operations. Timely detection of anomalies can empower you to prevent problems and curb their cumulative effects on business.
Data anomaly detection facilitates solving a broad spectrum of real-world problems:
- Early detection of financial frauds: Financial transactions with customers or partner businesses need to be processed securely. Detecting anomalies in transaction patterns can uncover security vulnerabilities and prevent potential frauds.
- Early detection of health issues: In healthcare, timely anomaly detection can help prevent the development of serious issues. If a patient’s vitals are detected to be beyond the normal range, it acts as a health warning demanding immediate attention. Besides helping individual patients, anomaly detection can also highlight concerns for public health, such as possible epidemic outbreaks.
- Preventing waste of resources: The Covid-19 pandemic has shown disturbing instances of misuse of government resources. This includes examples of fraudulent unemployment insurance claims and stimulus checks going to dead people. Anomaly detection can help in such cases to recognize suspicious activities and prevent waste of resources.
- Managing demand surges: During the Covid-19 pandemic, shoppers grappling with long periods of lockdown started shopping online for several products. Naturally, the eCommerce companies struggled to anticipate and fulfill unexpected surges in demand. Recognizing the demand surge is essential for eCommerce companies to prevent chaos and disappointed customers. They can leverage anomaly detection to identify the key trends ahead of time and be prepared.
- Detection of hacking and intrusion attempts: IT security teams constantly monitor user behavior to discover patterns and detect irregular activities. Anomaly detection fortifies their attempts to identify intrusion attempts before any potential attack on sensitive information.
- Higher accuracy of analytical models: Early detection of outliers and data drift contribute towards improving the quality of data used to train the analytical models. As models work with better quality data, they deliver more precise results and improve their accuracy over time.
- Minimized data downtime: Automatic detection of data drift, outliers, or changes in patterns and schema helps continuously deliver high quality data to enterprise systems. By eliminating anomalies before they affect the downstream applications, you can minimize data downtime.
- Improved telecom service performance: With a large base of subscribers and extensive network traffic, telecom service providers need to monitor their performance continuously. Network degradation resulting in latency or jitter is a constant risk, which they must mitigate quickly. Telecom service providers rely on automated anomaly detection for detecting and addressing performance issues in real time.
- Enhanced cloud service performance: Identifying patterns in traffic, cloud service providers allot resources and ensure uninterrupted service. Anomaly detection enables them to discover potential breaches in security or breaks in service. Based on the analysis, they can assess the required infrastructure enhancements to continue delivering uninterrupted services.
- Superior customer experience: Any downtime for online businesses impacts the customer experience. Anomaly detection for service glitches, loading errors, and delayed response supports analyzing the risks of usage lapses. Faster real-time mitigation is critical before customers encounter downtime or other problems. With automated data anomaly detection, online businesses can continuously monitor systems to anticipate and address the challenges of customer experience.
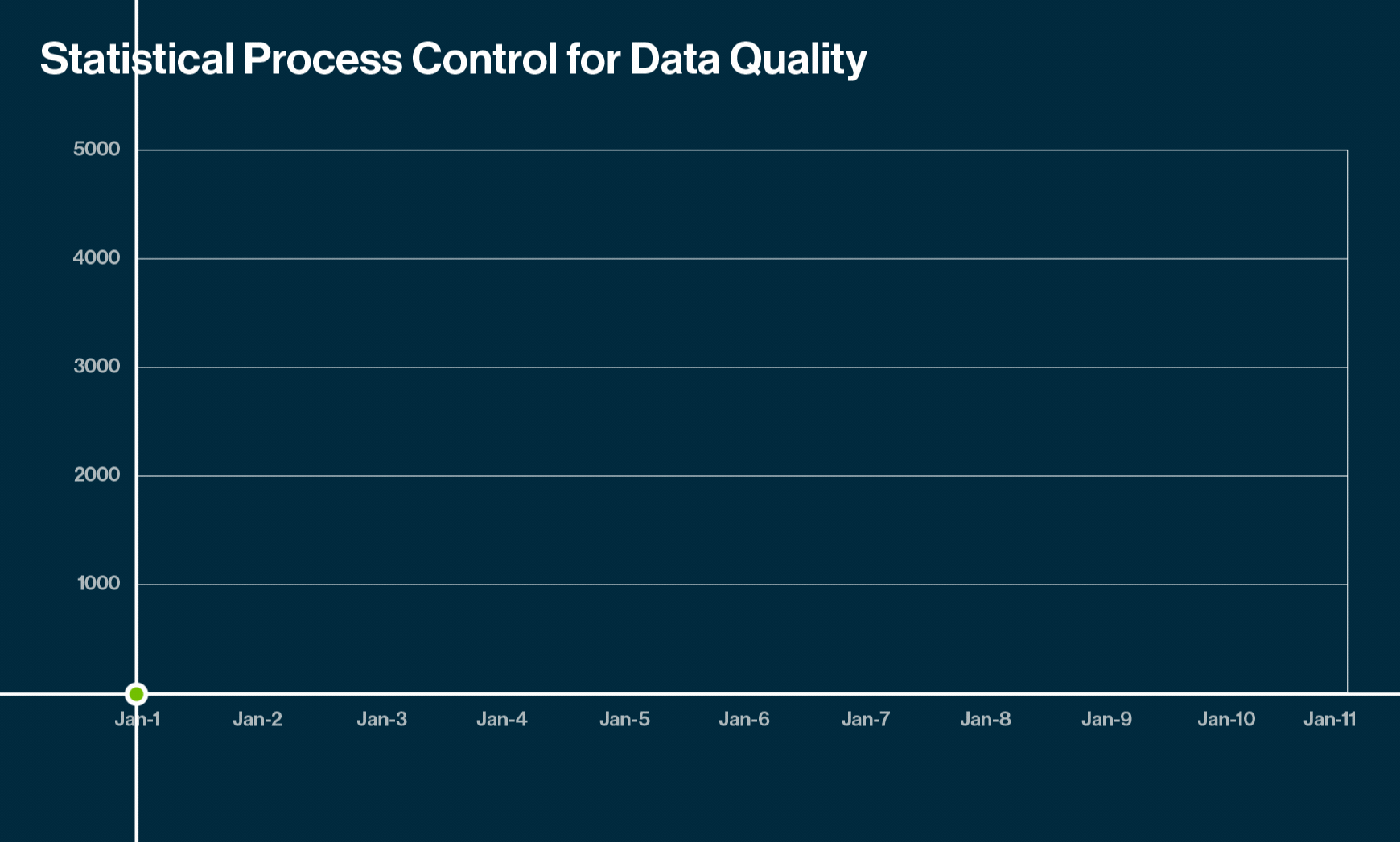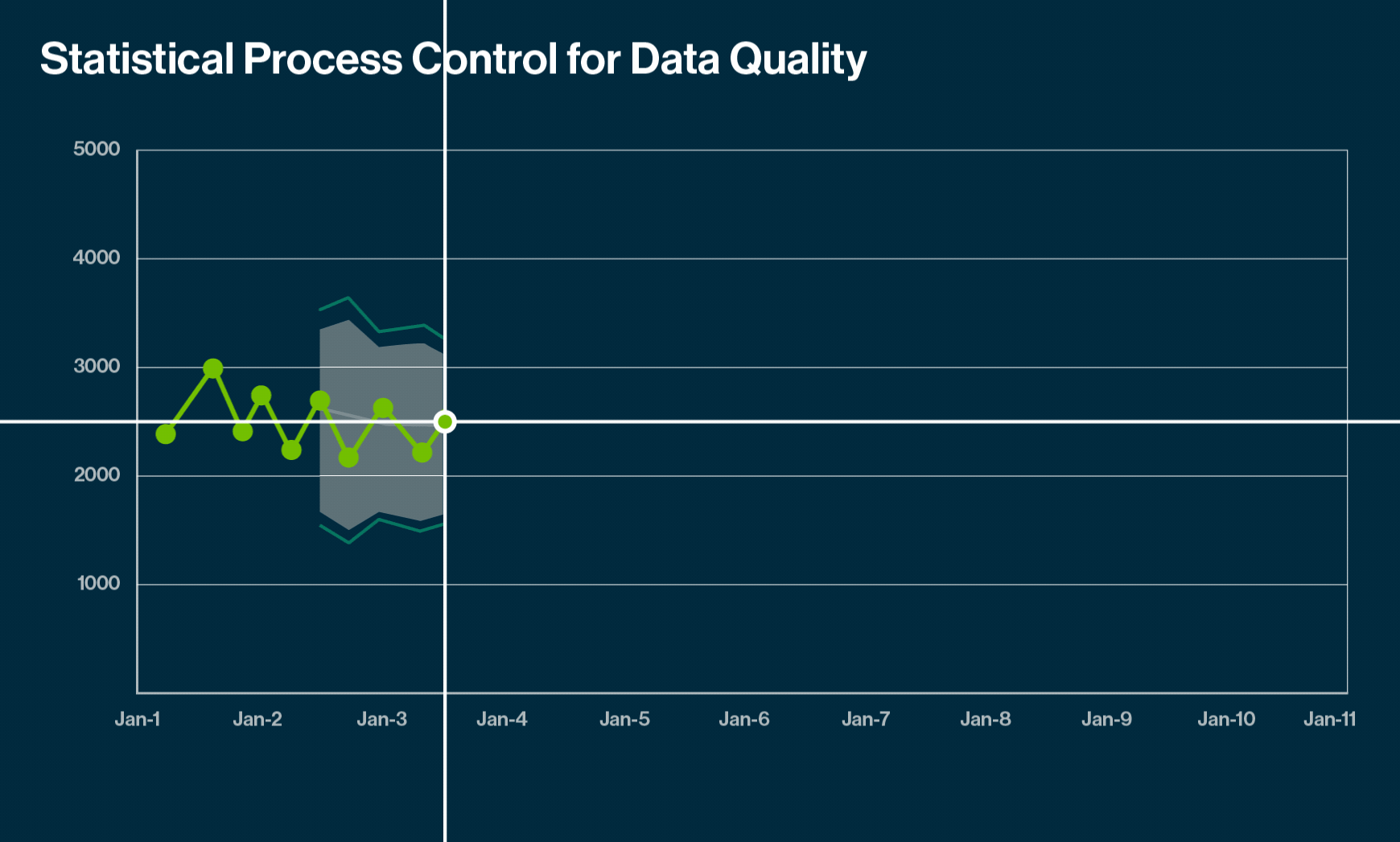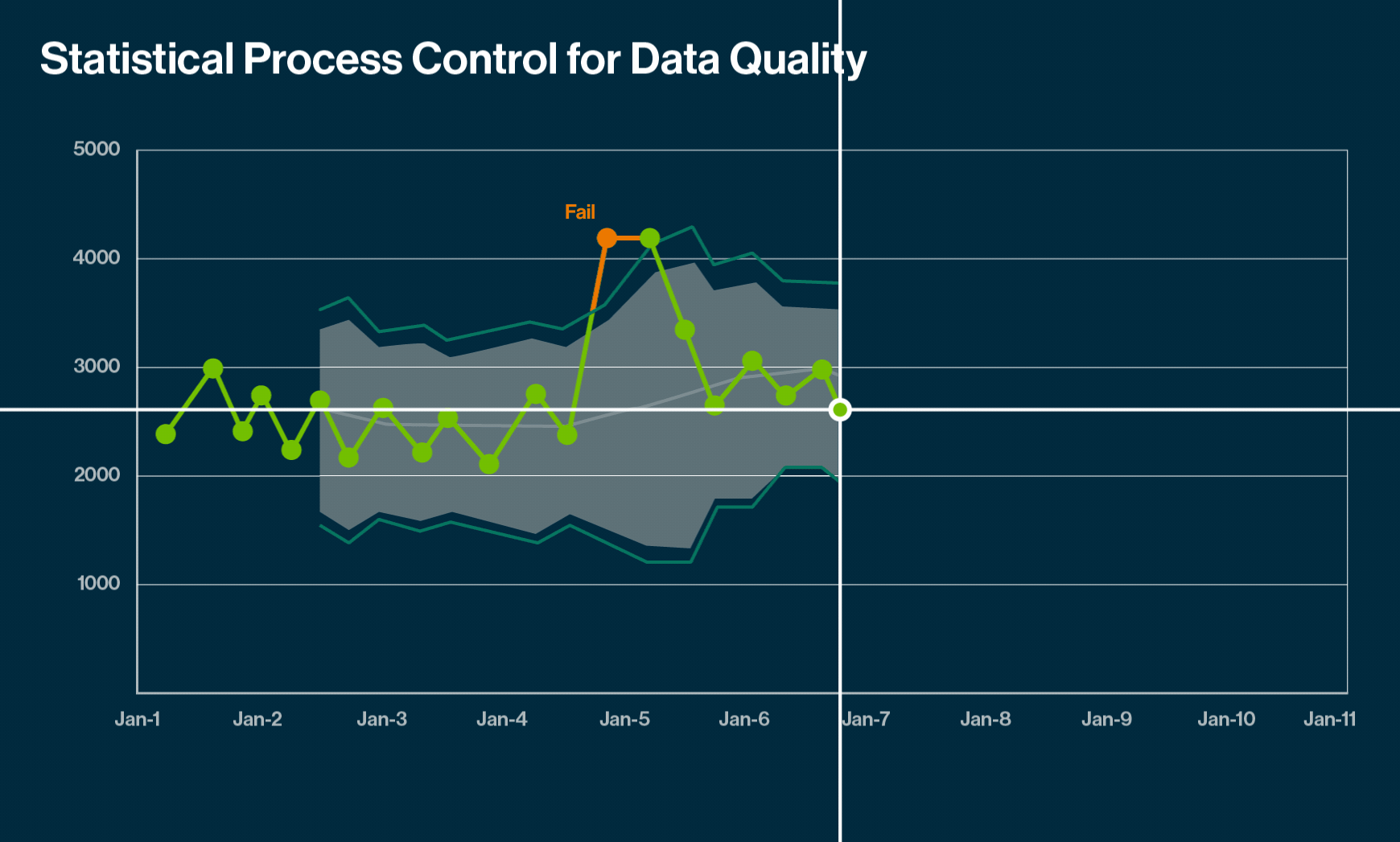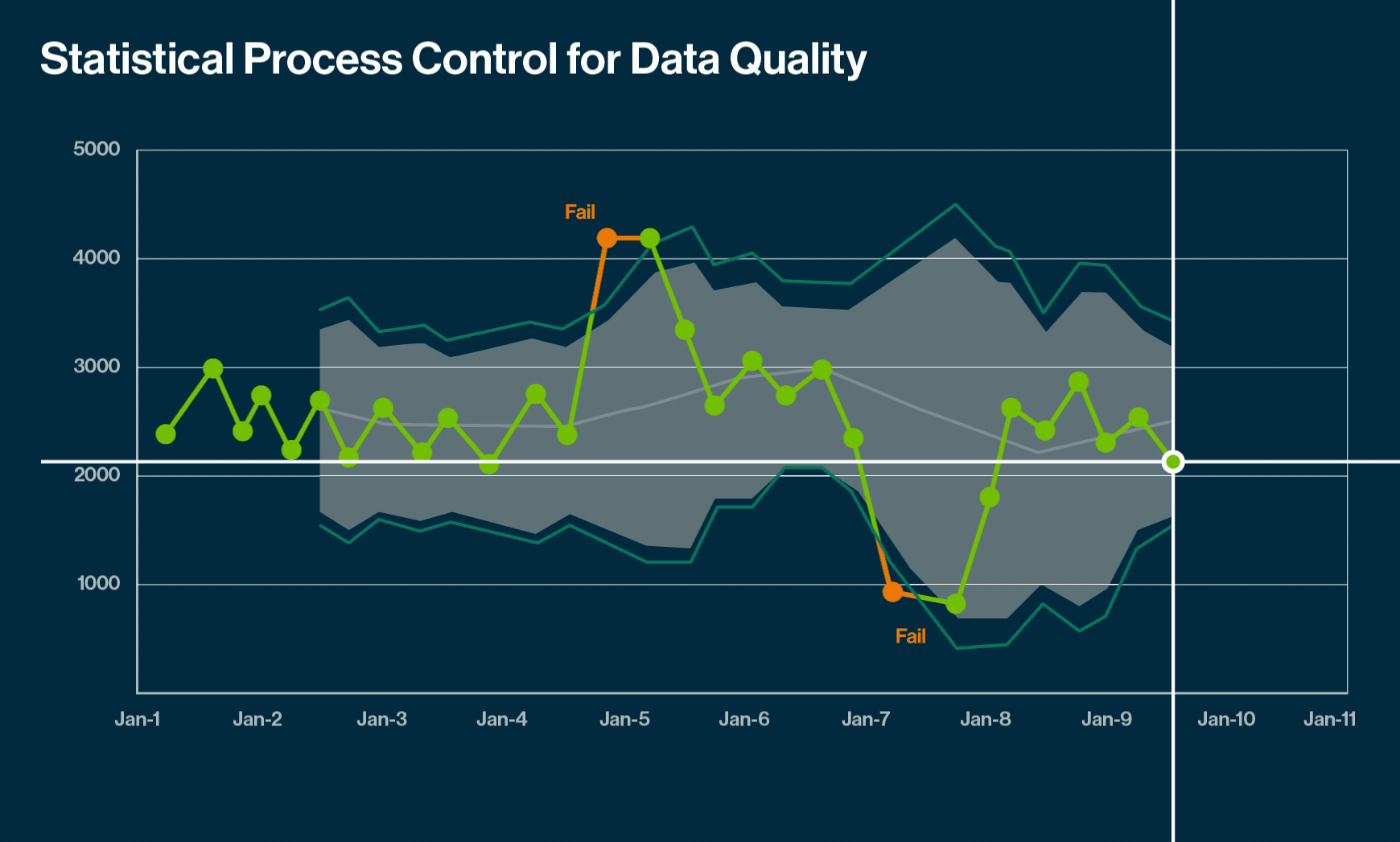
Anomalies tell you that some data points do not fit with others in the same set, but that need not always be bad. They reveal unusual stories and enrich our perspective with hidden insights.
A change in customer behavior patterns can also indicate potential opportunities. Contextual anomalies such as an uncommonly cold summer can be an opportunity to provide relief ahead of time and also plan for future occurrences. If one employee outperforms others in the current role, you can leverage her talent for higher responsibility. Child prodigies are usually discovered as outliers.
What matters is that you discover anomalies early and act on them fast.
Anomaly detection settings
Data anomaly detection relies on the assumption that anomalies are rare events, and they differ considerably from normal behavior. The detection process needs a context of normal behavior to recognize any abnormal behavior. Time series data provides the context with a sequence of values over time. Each point in the time series data has a timestamp and the metric value at that time. This context establishes a baseline for a normal behavior pattern, helping identify unusual patterns or outliers.
Enterprise data anomaly detection works with three different settings:
Point anomalies
Individual anomalies appearing very far from the rest of the data set. For example, a bank withdrawal of a large amount that has never occurred before is a point anomaly and a potential fraud case
Contextual outliers
Anomalies deviating substantially from the other data points in the same context. Note that an anomaly in one data set may not be an anomaly in another data set.
Seasonal fluctuations in power consumption, for example, are not contextual anomalies. On the other hand, a sudden demand for umbrellas outside its peak demand season is a contextual anomaly for an eCommerce company. It can indicate a fashion trend or a pricing glitch.
Collective outliers
A subset of data points that is an outlier to the entire dataset. The data points in this subset are neither point anomalies nor contextual outliers. Consider a situation where the stock price of a company remains the same for an extended period. As stock prices typically fluctuate at all times for most companies, this case is a collective outlier.
A well-constructed model representing the normal behavior sets the context to identify outliers. Modern systems use predictive ML algorithms for accurately forecasting patterns and detecting anomalies.
Challenges in anomaly detection
Modeling normal behavior to provide the correct context is the biggest challenge in anomaly detection. You may also find separating noise a major obstacle in identifying real outliers.
- Modeling normal behavior: Time-series provides the basic context for normal behavior to detect anomalies. But without the appropriate context for large, complex systems such as traffic patterns or environmental changes, identifying outliers is challenging. To make anomaly detection work at the enterprise scale, predictive data quality creates statistical sketches by collapsing raw data down into 100X smaller chunks to baseline and benchmark datasets over time. Modeling normal behavior with acceptable variance helps identify anomalies more accurately.
- Noise and poor data quality: In healthcare use cases, outlier detection rules are rigorous, identifying even small changes as candidates for attention. Noise and poor data quality can affect distinguishing outliers from normal records, reducing the effectiveness of anomaly detection.
- Streaming data volume: The high volume of streaming data may affect the processing speed. The scalable, ML-driven, predictive data quality can detect data drift and outliers in real time to provide early warnings.
- Deeper understanding of data: At times, datasets include extreme values that are not outliers or data quality issues. Understanding these values is a challenge, as the time-series context may not sufficiently interpret them. Data intelligence can provide the ability to understand and use your data in the right way. Connecting data, insights, and algorithms can uncover a deeper understanding of data for correctly identifying anomalies.
Benchmarking Anomaly Detection
Anomaly detection in specific contexts is challenging, with large streaming data volumes and the urgency of discovery. Machine learning algorithms accelerate the process and improve accuracy over a period through iterative learning.
The most common anomaly detection methods include supervised, semi-supervised, and unsupervised.
- Supervised detection: You can use this model with fully labeled training and test data sets, including labeled anomalies. Support Vector Machines (SVM) and Neural Networks algorithms work well for supervised detection, as they do not need labeled data or known anomalies. This model is not suitable when anomalies are unknown or not yet identified.
- Semi-supervised detection: When you have fully labeled training and test datasets but not any labeled anomalies, semi-supervised detection works the best. The system learns normal behavior and identifies deviations or outliers. Several algorithms are available for semi-supervised anomaly detection, including one-class SVM, Gaussian Mixture Models (GMM), and Kernel Density Estimation.
- Unsupervised detection: Predictive data quality uses this flexible model for datasets with or without any labels and without any identified anomalies. It scores data based on characteristics and does not need any predefined normalcy values. Isolation Forest, Principal Component Analysis (PCA) and K-means are some of the best algorithms for unsupervised anomaly detection.
With predictive data quality, you can leverage automated, real-time, early anomaly detection for a diverse range of business cases.
Watch the on-demand Product Showcase for Collibra Data Quality! This webinar highlights how you can build high quality data pipelines and data products by continuously monitoring data movement. It also focuses on the importance of automating data quality checks at every point in your DataOps journey!
-

Ankur Gupta
Ankur Gupta
Director Product Marketing
Collibra
Share on:
Related articles

Data QualitySeptember 12, 2024
What is data observability and why is it important?

AIJuly 15, 2024
How to observe data quality for better, more reliable AI

Data QualityNovember 8, 2024
Announcing Data Quality & Observability with Pushdown for SAP HANA, HANA Cloud and Datasphere

Data QualityNovember 16, 2023
The data quality rule of 1%: how to size for success
Keep up with the latest from Collibra
I would like to get updates about the latest Collibra content, events and more.
Thanks for signing up
You'll begin receiving educational materials and invitations to network with our community soon.