How machine learning is revolutionizing upstream data observability and downstream data quality
Share on:

The Gartner Sixth Annual CDO Survey identifies data quality as the top objective for Data & Analytics leaders. And it is not surprising. To make data-driven decisions, you need high quality data that you can trust. But enterprise data comes from various sources and can contain errors or discrepancies. That is why organizations need to make data quality a top objective of their data and business strategy.
Is your data quality where it should be?
Most organizations have some data quality programs in place. They have standard or home-grown tools, manual or partially automated data quality rules, established processes, data stewards, and statistical reports. But as the volume of data and data-driven activities multiply rapidly, there are a lot of questions that arise, such as:
- Does the data quality program meet the set targets?
- Is it able to scale with data?
- Can it deliver trusted data in near-real-time?
- Does it detect problems in advance?
- What are the challenges in meeting the targets?
The March 2022 Gartner report on the State of Data Quality Solutions shows that data quality use cases are now pervasive across all business activities. It also notes that the traditional data quality tools fall short of data quality needs due to significant manual efforts, limited scope, and outdated technologies.
If your data quality is not where it should be, it needs a critical rethinking. The speed and volume of data are skyrocketing. Data pipelines are growing to demand focus on data in motion in addition to data at rest. Storage and applications are moving to cloud platforms. IoT data is fast becoming a major contributor to enterprise data, and it is more unstructured than ever.
All these changes indicate a substantial shift in the ways of managing data. There are countless opportunities to unlock the value of this data, no doubt, but they are not without challenges. Especially when you want to drive critical business decisions with this data, and you want to assure continuous high data quality.
Why is machine learning the right fit for data quality?
While some organizations still rely on traditional data quality tools, many have harnessed automation to improve issue detection. The current crop of modern tools has also streamlined the data quality process to some extent for faster issue resolution.
However, detecting and fixing issues is just the first line of defense for data quality. And this reactive approach is not enough anymore. The speed, volume, and diversity of data today are so massive that the quality rules alone cannot cope. In fact, over 70% of rules degrade in less than 6 months and lose their value. Handling data quality in an efficient way demands a more proactive approach. This approach focuses on identifying and preventing quality issues before they can happen.
The two-part proactive approach
With the two-part proactive approach you must first identify potential problems and then prevent them. How can you identify potential problems? To begin with, it requires observing data constantly as it arrives. It also calls for understanding the context around the data. Moreover, you need to know the expected correct data first to recognize the incorrect data. The next task of preventing potential problems requires finding the root cause and fixing it upstream.
All this must be in near-real-time, at the speed of streaming and collecting data, and at the vast scale and diversity of it. Here, machine learning can be a great fit.
Machine Learning and data quality
Machine Learning (ML) technology uses data and algorithms to enable systems to learn continuously and improve their accuracy. The more opportunities ML gets to learn, the more experience it builds in the given task. The best part of ML is that its accuracy keeps improving with experience.
ML has been around for a long time, but its business applications have surged only in recent years. Its key strengths of pattern recognition and self-learning are used widely in several verticals. Both of them work very well for data quality. ML models can learn to find hidden patterns in data and identify outliers. They also learn from the large amount of data to self-generate data quality rules. This ability of auto-discovery opens up the entire universe of enterprise data to ML.
Diversity and a high volume of data are never a problem for ML. In fact, more data helps fine-tune the ML models and helps them evolve with data.
How does machine learning enhance data quality?
Continuous learning is the strong point of ML, along with the ability to handle large volumes of diverse data in real time. These aspects of ML help you enhance data quality through multiple features.
1.Auto-generated, adaptive, explainable data quality rules
Manual or automated rules work for known issues. However, the unknowns in data are rising with the increasing complexity of data. Detecting the unknowns requires next-level technology, and ML fits there very well.
ML can examine data and auto-generate rules that can proactively surface quality issues in real time. These rules can adapt themselves as they work on new data. With more data, they can predict and detect the unknowns more accurately. The auto-generated rules do not need domain experts and rule writers. Making the rules explainable helps you in understanding and sharing them easily. In several cases, The auto-generated predictive rules have considerably speeded up migration and compliance.
2.Detecting anomalies
ML models can discover patterns in data and effectively detect when data does not fall in the expected range. Anomaly detection quickly identifies potential data issues, which can be critical in several financial or healthcare cases. For example, spotting unusual financial transactions can raise a fraud alert. In healthcare, detecting vitals outside the normal range can help save lives.
You can train the models to recognize data quality issues specific to your use cases and prevent potential failures.
3.Identifying duplicates and missing data
Data quality issues often boil down to incomplete and duplicate data. Both affect analytical insights and business decisions. Duplicate data may waste marketing budgets by targeting the same customer again and again. Missing data, on the other hand, can make you miss out on great opportunities. Several inconsistencies also surface while reconciling data across diverse sources. But locating them in the enormous volume of data is a nightmare.
ML models are very efficient in matching records and resolving these issues. In addition to identifying missing records, they can assess and fill those gaps, too. The models constantly improve their accuracy as they work on more data. You can easily update the matching logic required for specific use cases.
4.Assessing impact and root cause of failures
Businesses do not just work with data at rest, but also with data in motion when data pipelines feed the downstream systems. Monitoring pipelines for issues and fixing them in real time can be challenging.
ML simplifies the work of your data stewards by learning to identify and classify potential issues. The ML models can be trained to assess the impact and automatically assign priorities for effective quality management. With the right training, ML models can also infer lineage to determine the root cause and help fix it at the source.
5.Making recommendations for data quality improvement
The proactive approach to data quality aims to prevent potential data quality issues. It can also use the ability of ML models to learn from experience to identify more improvement areas. ML models can discover hidden patterns or connections and recommend improvements. For example, if an obsolete rule is causing unnecessary delay, ML models can detect and flag it.
The continuous learning of ML models delivers better and faster insights. According to the Gartner Sixth Annual CDO Survey, by 2024, 40% of organizations will deploy continuous learning to better support organizational shifts toward real-time performance.
Augment, automate, and simplify data quality with machine learning
The use of ML augments the data quality lifecycle to automate the traditional data quality practices or add more efficient new practices. The March 2022 Gartner report on the State of Data Quality Solutions notes that augmented data quality capabilities disrupt how we solve data quality issues. This disruption fueled by metadata, ML, and knowledge graphs is bringing new practices through automation to simplify data quality processes. Machine-led and human-governed data quality can provide better insights by discovering patterns, trends, and relationships of data.
Predictive data quality uses ML to understand the data errors that occurred before and the way they were corrected, and learns to look for potential errors. Here, ML models supplement the current efforts to improve the efficiency and productivity of data stewards. They also automate rule discovery and adaptation to improve the speed and accuracy of results. In essence, ML models don’t replace your organization’s existing framework. They rather augment the current practices of data governance, automation, and stewardship to boost data quality.
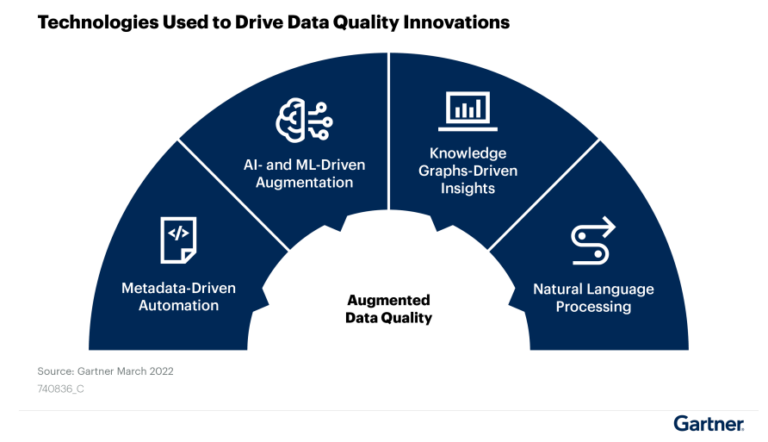
Gartner strongly recommends using ML with automation for semantic discovery and anomaly detection, as well as for data quality rule generation and assignment. Sophisticated data quality solutions also leverage metadata to build context around the potential data quality issues. The context helps to understand and assess the issues better. The use of knowledge graphs for automated discovery and predictive approach is picking up. The synergy of all these technologies brings flexibility and agility to data quality.
Conclusion
Data quality is one of the key business goals for organizations today. It represents the constant quest for rapid analytics and trusted business decisions. ML is revolutionizing the approach to data quality, to automate the rule-based solutions and augment the current efforts.
The ML models improve as they work with more data, helping simplify data quality processes and enhance trust in data. Forbes highlights that once ML has begun the data quality journey, subsequent data can become stronger. This can create a snowball effect where the longer you have implemented ML, the more value you’re extracting from your data, and the more valuable that predictive technology also becomes.
With ML, you can scale easily to harness the speed and diversity of data for a competitive advantage. A robust foundation of ML also makes you ready for the emerging and future data ecosystems, which need augmented data quality solutions recommended by Gartner.
-

Ankur Gupta
Collibra
Director Product Marketing
Collibra
Related resources
In this post:
Share on:
Related articles

Data QualitySeptember 12, 2024
What is data observability and why is it important?

AIJuly 15, 2024
How to observe data quality for better, more reliable AI

Data QualityNovember 8, 2024
Announcing Data Quality & Observability with Pushdown for SAP HANA, HANA Cloud and Datasphere

Data QualityNovember 16, 2023
The data quality rule of 1%: how to size for success
Keep up with the latest from Collibra
I would like to get updates about the latest Collibra content, events and more.
Thanks for signing up
You'll begin receiving educational materials and invitations to network with our community soon.