



Most people working on financial reporting see the underlying systems and data flows as some kind of magic black box. They know roughly where the data comes from, but do not know all systems that are involved and whether or not the data outputs are trusted sources of data. They may know Molly from the Accounting department forwards the bank balance sheets to Sam from the Risk department via email, but they do not know where else these files are handled and processed. They may want to know why the data quality of their data fell, but do not know where to look or which line of business to involve for a quick resolution on the matter. This explains why it takes banks many days before they can submit their reporting. Time they no longer have, according to the regulators. This brings about the need for financial reporting and data governance in any such organizations tackling the above questions.
Regulations such as BCBS 239 demands timely and accurate reporting. Such principles are those which regulators will use on any reports submitted by banks. The only solution is to put the data into the hands of the users who are responsible for it and to create transparent data flows and processes that show exactly how data flow to cells in a COREP or FINREP report along with any files and people involved in such processes.
The mission to find information – and not only information, but TRUSTED sources of information, daily – needs an ultimate battle plan via data governance.
The Financial Reporting Standard (FinREP) framework governs the reporting of financial information on an annual basis, while the Common Reporting Standard (CoREP) framework governs the reporting of risk (credit, market, operational, solvency, capital) on a monthly and quarterly basis. CoREP reporting came into effect from 1st January 2014, and full implementation is required by 1st January 2019.
Why do financial institutions want to apply data governance?
New regulatory challenges require trustworthy data. The governance objective (principle 1 out of 14) is needed to ensure the bank adheres to these principles because governance drives changes. These 14 principles are used by banking regulators in order to check for compliance and for audit of data as Risk Data Aggregation and Regulatory Reporting.
Why not keep doing what they do now?
Financial institutions are identifying the underlying issues that come without having a proper data governance initiative in place. One cannot aggregate, report, and share data across silos without tags, common messaging protocols, and underpinning standards. Good data governance is necessary to speak the same language across your organization.
Having excel spreadsheets from departments and not knowing who owns it, not knowing where the data originates from and whether it is certified and approved data, not knowing how it is processed across various phases of data consumption or aggregation at any point in time, is not an option anymore.
So, how do financial organizations comply with government regulations like BCBS 239, Solvency II, and CCAR reporting for FinREP and CoREP reporting required by European Banking Authority EBA? How do we maintain trust in the data?
Collibra addresses all these questions as well as end-to-end data traceability for your reporting purposes. The idea is to facilitate in governance of new European reporting frameworks which harmonizes supervisory reporting standards for regulated institutions across the EU. The interactive Data Point Model that governs these reports can be found here: http://datapointmodel.eu/
What is Data Point Modeling?
Data Point Model methodology intends to create a link between the functional design of a reporting framework – “the reporting templates” – and the technical design of an XBRL taxonomy that is being demanded by the EBA for FINREP and COREP reporting.
Different data points in a report may have different types of attributes linking further details about the reporting point. This is how a typical data point might look like in a FINREP F 07.00.
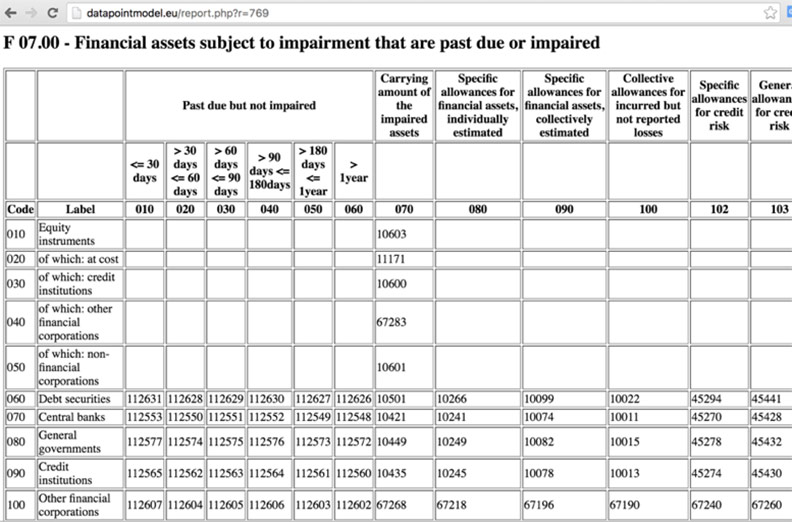
The intersection of a row and its corresponding column make up a valid data point. The Data Point Model is a method developed by BR-AG – a company that is specialised in XBRL related technology. It is a multidimensional data that describes each data point with various categories like Base, Metric, Accounting Portfolio, and so on.
Some of the ways Collibra can be used for data point modeling:
Document all your data points, reporting attributes, and source systems and link them to the right compliance, regulation paragraphs, and so on.
Answer your organizational questions – where is this report value coming from? Which table / column does this data point refer to? And more.
Use the Collibra Center of Excellence’s out-of-the-box workflows and metamodels to govern and manage data related to these reporting compliance and regulations.
Why start from scratch when the work has been done for you? You can bring in your metadata from ERWin / ERStudio or any other data modeling tools (as long as they accept Java and REST APIs), and use Collibra Connect’s integration template for ensuring governance of your data models, taxonomies, hierarchies, etc of your metadata.
Understand how to make a regulation requirement be accessible both to regulators and the reporters including the producers and consumers of data along the way of data flow.
Including translation of the DPM in the Solvency II XBRL taxonomy.
Increase and ensure trust in your data, along with proper ownership and governance around it.
Some of the common problems that financial institutions face are that these data points are currently stored in Excel spreadsheets and most stakeholders do not have access and understanding of what calculations are done in their systems related to these data points.
Where does the data come from? What controls have been put in place to improve trust and understanding of your organizational data?
Regulators and business users often want to know where the data comes from and what controls you’ve put in order place to improve trust and understanding. In the traceability, you can see all the systems and critical data elements that go into this report, together with the quality scores at many of the stages. Users can easily search across any data within Collibra – for example a business term – and link it back to its corresponding systems and ultimately the report as an example of having a full trace of data. Different views can be created for different users like IT and Business.
Identify and correct data quality issues.
If a data quality drops below threshold, Collibra automatically creates a data quality issue and notifies the right people to handle the issue according to the desired priority. Issue management is out-of-the-box.
With the above, you now have a war plan that you can build upon. It is crucial to realize your governance tool should be able to support your long term visions, scalability, accessibility, and performance. Our Collibra experts will be there to help you in case you need our assistance. You can leverage in our Center of Excellence team of experts in data governance, Collibra product, technology and enterprise information management with extensive implementation knowledge to provide thought leadership and leading practices to accelerate Collibra implementations.
The Collibra Center of Excellence is responsible for producing vertical and use case-based accelerators for Collibra product implementations. Accelerators include pre-configured operating models, integration templates, content, etc.
Why start from zero when you can start from one?

