



Data governance is a very intricate field, so implementing and sustaining data governance comes with a suite of challenges. Luckily, thousands, if not millions, of organizations use data governance to improve their operations, so you can learn from others’ mistakes and successes. Below are a few of the data governance best practices that Data Intelligent organizations employ when maintaining and amending their data governance programs:
- Focus on the operating model
- Identify data domains
- Identify critical data elements within the data domains
- Define control measurements
- Promote consistent communication
- Measure your goals with metrics
We’ll start by defining data governance and a data governance framework, and then we’ll elaborate on the six most important data governance best practices.
What is data governance?
Data governance is the practice of managing and organizing data and processes to enable collaboration and compliant access to data. Data governance allows your data citizens — and that’s everyone in your organization — to create value from data assets.
Data governance is an organizational discipline. It is supported by technology, but not a technology in itself. True data governance employs a data governance framework that aligns your organization around data to maximize its value.
What is a data governance framework?
A data governance framework articulates your data governance strategy from ideation to execution. Implementing a data governance framework affects various components of your data management process. Using a data governance framework encourages organizations to dive deeper into enterprise goals and challenges — the result: teams can precisly identify needs and achieve fast, measurable, and scalable results.
What are data governance best practices?
Best practices come from experience, so it’s always a good idea to look around and consider what other organizations have done when implementing and working with a data governance program. One of the best things you can do is start small and build your data governance program from there. This will help you test strategies and figure out what works best in your unique environment.
Data governance best practices are a set of recommendations that we’ve identified based on the successes we’ve seen with our customers. Our best practices can help ensure that your business gets the most out of its data governance program. We’ll discuss what we think are the six best practices for a data governance strategy below.
Some of these can be big-picture strategies, including clearly defining and communicating your organization’s vision and goals for your data governance program and making sure to measure your progress in several different ways. Others can be more technical, such as regularly participating in enterprise data architecture reviews or emphasizing automation when it comes to data requests and permissions, workflows, and approval processes.
1. Focus on the operating model
An operating model, sometimes referred to as an asset model, outlines how an organization defines roles, responsibilities, business terms, data domains and more. This, in turn, affects how workflows and processes function. It impacts how an organization operates around its data.
The operating model is the basis for any data governance program. The idea is to establish an enterprise governance structure. Depending on the organization, the structure could be:
- Centralized (a central authority manages everything)
- Decentralized or federated (there are multiple groups of authority)
Operating model example
Here is an example of how an insurance company working with Collibra set up its operating model:
The insurance company is cross-functional, frequently requiring collaboration among different lines of business, such as finance, sales, marketing and IT. The departments each have different data governance representatives, business stewards (owners of data) and technical stewards (owners of the infrastructure supporting data). Stewards form groups that roll up to the head of business lines, and business lines roll up to the leaders of business and IT.
As a data governance best practice, the company created an enterprise data governance structure and formed a corporate data governance council reporting up to the Chief Data Officer. It is important to define the realm of ownership across your organization. Determining authority will help socialize your data governance program and establish an intelligence structure to tackle data programs as one unit of force.
Members of the business and IT form different groups and align to a reporting structure often referred to as the data governance council or the data stewardship committee. The council discusses everyday data concerns, makes decisions and disseminates the information across the organization. The data governance council ensures formalized ownership, and determines the right tools and technology to support stewards so they can perform their job efficiently.
Below is an example of roles and responsibilities across an organization, determined by the operating model:
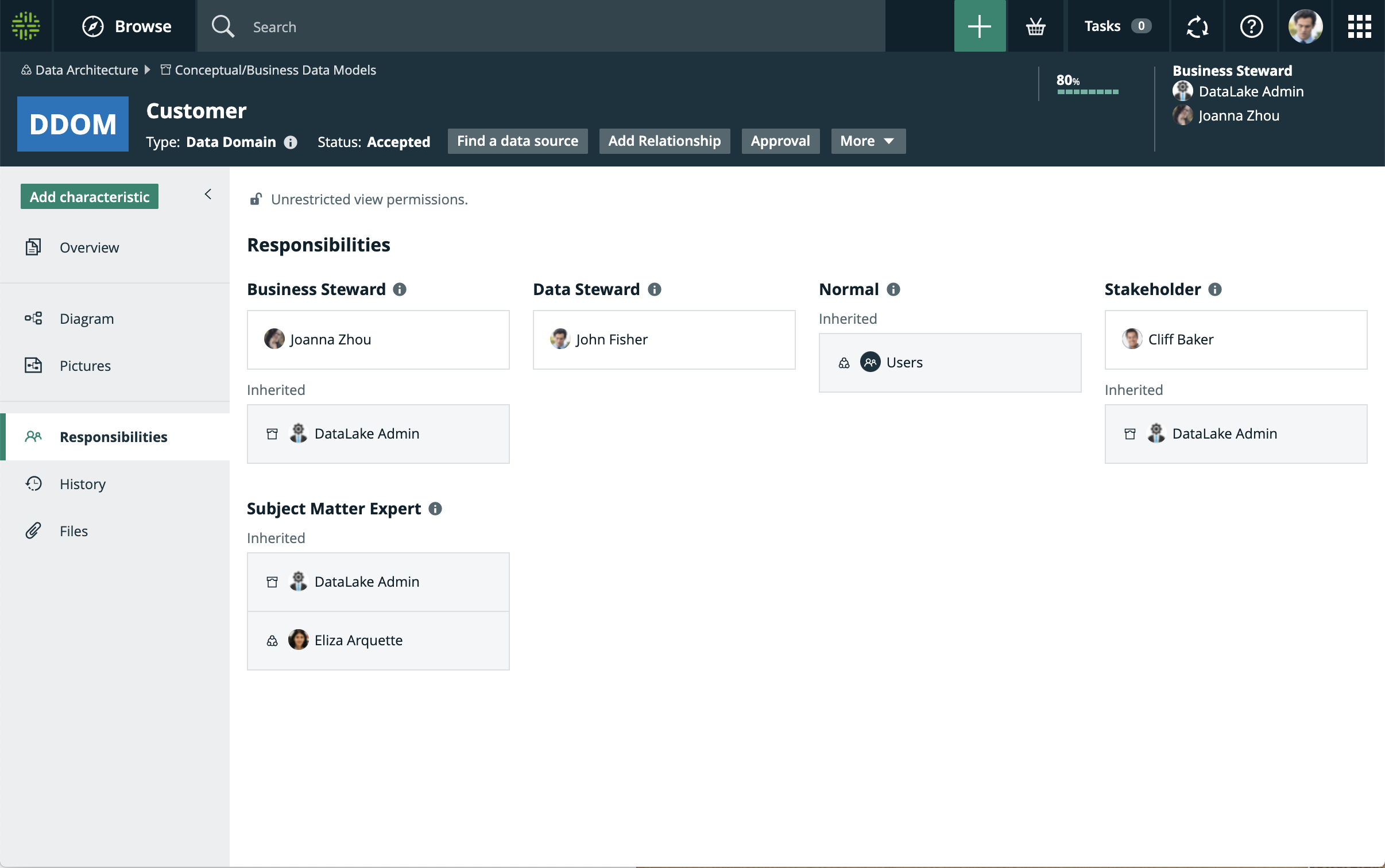
For more data governance best practices regarding an operating model, check out this video about how Progressive set up a system of ownership across the organization.
2. Identify data domains
After establishing the data governance structure, the data governance best practice is to determine the data domains for each line of business. The most famous examples include customer, vendor, and product data domains. Each data domain contains the following artifacts:
- Data owners
- Business glossaries
- Data dictionaries
- Business processes
- Data catalogs
- Reports catalogs
- Data quality scorecards
- Systems and applications
- Policies and standards
Typically, organizations identify data domains when they run into problems.
What is data domain in data governance?
Usually, a data domain–especially in the context of your data governance system–represents a specific grouping of data that’s logical.
So, in other words, a data domain will be a grouping of data that has something interrelated or in common.
A specific data domain might have a common concept, a similar purpose, relate to an organizational structure, or pertain to a specific sector inside (or outside) of your organization.
The most famous examples include customer, vendor, and product data domains. Each data domain contains the following artifacts:
- Data owners
- Business glossaries
- Data dictionaries
- Business processes
- Data catalogs
- Reports catalogs
- Data quality scorecards
- Systems and applications
- Policies and standards
Why does this matter for your organization? And further, why do data domains matter for your data governance best practice plan?
Firstly, because having a stellar data domain system in place can help play an increasingly important role in identifying data and empowering your data citizens to not only better manage the data enterprise-wide, but also address data issues before they happen.
But typically, organizations identify data domains when they run into problems.
Data domain example
Here is an example of a financial services firm that overcame its data challenges and followed the data governance best practice of identifying data domains.
The firm had difficulty gaining visibility into its data and wanted to gain more insights on its customers. It had a number of requirements, all tied to these business problems; for example, the requirements included:
- Increase customer experience
- Control over validating customer needs
- Manage customer usage
- Increase upsell on storage billing cycles
Data was spread across multiple systems and applications with no defined ownership.
The firm created ownership by identifying key stakeholders, business processes and data sets related to the customer domain and established control around its lifecycle. This gave data users a clear understanding of where data comes from, who owns it, when it changes and who should be involved.
Here is a sample diagram for the data domain “Customer,” showing end to end data lineage across the data domain:
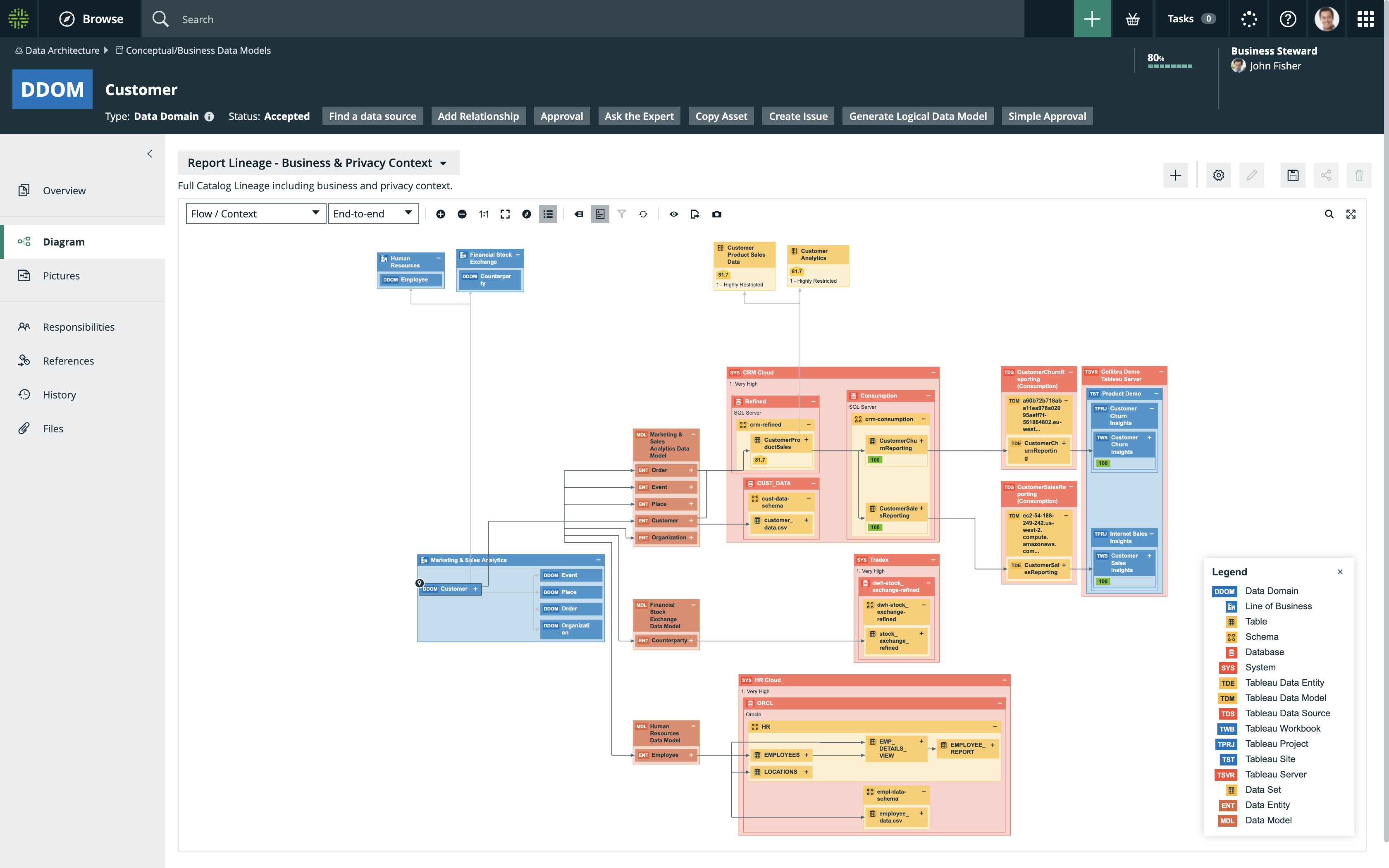
3. Identify critical data elements within the data domains
After defining the data domains, the next data governance best practice is to identify the critical data elements. In the lineage diagram above, evidently, data domains touch 10s, 100s, and 1000s of systems and applications containing key reports, critical data elements, business processes and more. In the early stages of your data governance program, there is no need to boil the ocean by focusing on all the data artifacts at once. The data governance best practice truly is to identify only what’s critical to the business.
A recent example of this data governance best practice in the Collibra Community comes from a technology company. The company needed data governance to validate customer reports and related source systems. During the first stage of implementation, the company identified just the ten most important reports and documented information about the systems of origin. Later, it scaled the initiative, applying certification requirements and related source system information for all reports. Simply put, a report is not certified if the owners cannot show its traceability all the way down the system of origin.
4. Define control measurements
The next data governance best practice is to set control measurements to sustain the data governance program. Data governance is not a one-time project. It is an ongoing program to fuel data-driven decision making and create opportunities for business. It prepares an organization to meet business standards. Control measurements include the following key activities:
- Defining automated workflow processes and thresholds for approval, escalation, review, voting and issue management
- Applying workflow processes to the governance structure, data domains and critical data elements
- Developing reporting on program progress
- Capturing feedback through automated workflow processes
For example, when one of Collibra’s technology customers in California started with their data governance initiatives, it began by defining ownership when assembling their data governance team, roles and responsibilities; defining business data definitions; and applying workflow processes to include data stewards in the change management process.
In the end, it established a robust data governance organization supporting an ongoing program. The company used Collibra as the system of engagement for managing all definitions and executing control processes, such as onboarding, approvals and capturing of feedback.
5. Promote consistent communication
One of the benefits of data governance is that it helps create a shared language, so it is only fitting that efficient communication is a best practice for data governance. There are three segments on data governance communication to consider: buy-in, onboarding and adoption.
Buy-in
Data governance affects every part of the organization; so, make sure leaders of every part of the organization understand its value. Communicate to executives how data governance will help them reach their strategic goals and what the risks and consequences are if they do not participate. By getting executive buy-in, you have a better chance of receiving funding and resources and driving adoption among the various departments.
Onboarding
Unfortunately, you cannot just snap your fingers and every data citizen knows the ins and outs of data governance; you’ll have to train them on data governance processes. This requires educating them on the value of data governance and communicating how it affects their everyday lives. By personalizing the communications, you can inspire the data citizens to want to learn more about data governance.
Adoption
Lastly, you need to consistently communicate data governance’s value so executives and everyday users alike will adopt data governance practices and technology. You can do this by:
- Embedding alerts and notifications about data governance in your tools
- Holding onboarding refreshment sessions
- Reporting on data governance metrics and progress
- Providing updates on policy changes and issues
6. Measure your goals with metrics
Lastly and certainly not least, a crucial data governance best practice is measuring your data governance efforts. Your team needs to evaluate the data governance program’s progress and its impact on the rest of the organization.
This data governance best practice tends to be the most challenging for organizations, but it is an essential element to powering continuous improvement.
The first step is to understand and define what success looks like. Success at your organization will not look like success at another organization. Success will depend on what your organization’s overall objectives are. Ask yourself and your teammates
- What does a successful data governance program look like?
- What does it mean to achieve Data Intelligence?
- How will we know when we achieved Data Intelligence?
Once, you can answer the above questions, you can identify your goals and evaluation criteria. Your key performance indicators should relate directly to your organization’s objectives and strategies. Some areas to track are
- Data dictionary and business glossary development – track how many terms and assets you upload to your system
- Access – track how long it takes users to obtain the information they need
- Adoption – measure how many employees use your data governance technology, how often, and for how long
- Issue management – count how many data related issues your organization logs and evaluate how well the team resolves these issues, how many issues the team resolves, and how long it takes to resolve them
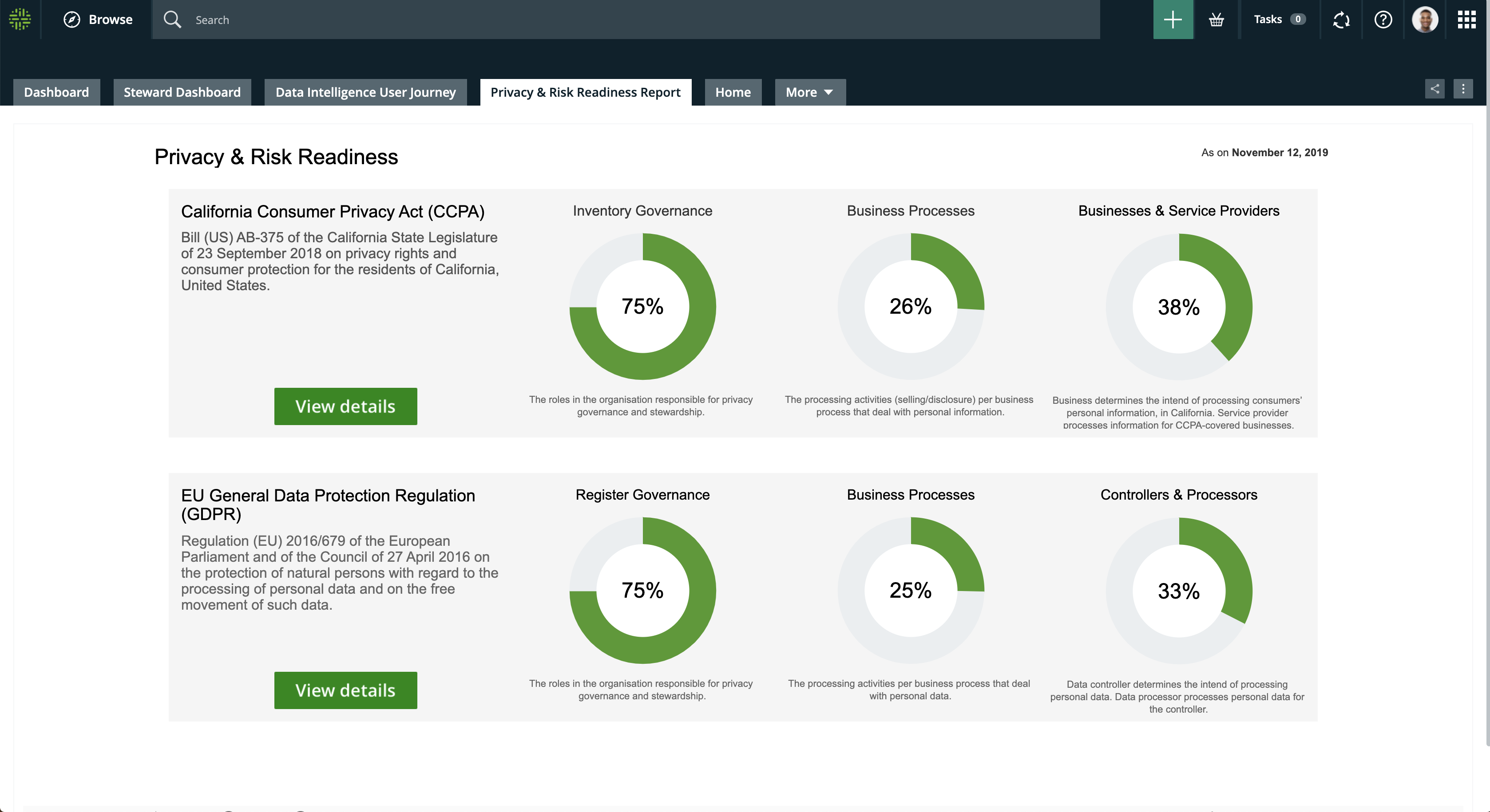
- Data quality – monitor the cleanliness of the data available and its fit for purpose
- Policy compliance – measure to what extent your organization adheres to standards set by internal teams and external regulators (see figure below)
- Reusability and scalability – keep a record of which processes your organization follows the most often and how they evolve over time
- Financial ROI – calculate the financial impact that data governance has on the organization
These are just some of the data governance best practices that Data Intelligent organizations follow. And depending on the industry, there are different approaches. To learn more about data governance practices and how they generate positive business outcomes, check out these success stories.


